Die gängige Praxis, den Erfolg von Programmierschnittstellen (APIs) primär an der absoluten Anzahl von Anfragen (Requests) zu messen, ist fundamental fehlerhaft. Diese Kennzahl, ein klassisches Beispiel für eine sogenannte „Vanity Metric“, erzeugt ein trügerisches Gefühl des Fortschritts, während sie kritische Aspekte wie Qualität, Effizienz und tatsächlichen Geschäftswert verschleiert. Dieser Artikel dekonstruiert systematisch die Schwächen dieses Ansatzes anhand eines realen Szenarios aus einem großen Unternehmen. Es führt etablierte Managementtheorien — insbesondere das Gesetz von Goodhart und den Kobra-Effekt — ein, um die kontraproduktiven Verhaltensweisen zu erklären, die durch solche Kennzahlen gefördert werden. Abschließend wird ein robustes, mehrdimensionales Framework aus handlungsorientierten („actionable“) Metriken vorgestellt, das operative Exzellenz, die Akzeptanz durch Entwickler und den Beitrag zum Geschäftserfolg umfasst. Ziel ist es, einen klaren, evidenzbasierten Fahrplan für den Übergang von oberflächlichem Reporting zu einer differenzierten, datengestützten Strategie zu liefern, die technische Leistung mit greifbaren Geschäftsergebnissen in Einklang bringt.
1. Die trügerische Verlockung der großen Zahlen
In vielen Unternehmen ist die Präsentation von API-Erfolgsmetriken ein fester Bestandteil von Sprint-Reviews. Ein typisches und weit verbreitetes Beispiel ist die Aussage: „Wir haben in diesem Jahr bereits 25 Millionen API-Anfragen verzeichnet, eine Steigerung gegenüber 23 Millionen im gleichen Zeitraum des Vorjahres.“ Auf den ersten Blick scheint dies eine klare und positive Entwicklung zu signalisieren — mehr Nutzung, mehr Aktivität, mehr Erfolg. Diese Erzählung ist intuitiv ansprechend, aber bei genauerer Betrachtung gefährlich simpel und oft irreführend.
Der Kern des Problems liegt in der Unterscheidung zwischen zwei Arten von Kennzahlen: Vanity Metrics und Actionable Metrics. Eine Vanity Metric ist eine Kennzahl, die „Sie gegenüber anderen gut aussehen lässt, Ihnen aber nicht hilft, Ihre eigene Leistung so zu verstehen, dass Sie daraus zukünftige Strategien ableiten können“. Solche Metriken sind typischerweise einfach zu messen, entbehren aber jeglichen Kontexts und können daher in die Irre führen. Beispiele hierfür sind die Gesamtzahl der Seitenaufrufe einer Website oder die Summe aller registrierten Benutzer eines Dienstes. Eine hohe Zahl an Seitenaufrufen verliert schnell an Bedeutung, wenn die meisten Besucher die Seite sofort wieder verlassen (hohe Absprungrate). Ebenso sind 10.000 registrierte Konten wenig wert, wenn nur 100 davon monatlich aktiv sind.
Im Gegensatz dazu stehen Actionable Metrics, also handlungsorientierte Kennzahlen. Diese sind als „klar definierte Messgrößen, die wertvolle Einblicke in Bezug auf Geschäftsziele liefern“ zu verstehen. Der entscheidende Unterschied besteht darin, dass eine handlungsorientierte Metrik eine fundierte Geschäftsentscheidung ermöglicht. Sie beantwortet nicht nur die Frage „Was ist passiert?“, sondern auch „Warum ist es passiert und was sollten wir als Nächstes tun?“.
Die fortwährende Nutzung von Vanity Metrics wie der reinen Request-Anzahl ist nicht nur ein technisches Versäumnis, sondern wurzelt tief in der Unternehmenskultur. Solche Zahlen sind leicht zu erheben und zu kommunizieren. Sie vermitteln ein „gutes Gefühl“ und umgehen die Notwendigkeit, sich mit komplexeren Fragen nach Qualität, Effizienz oder tatsächlicher Wertschöpfung auseinanderzusetzen. In einem zeitlich begrenzten Sprint-Review bietet eine einzelne, positiv verlaufende Zahl eine bequeme Abkürzung, die eine Illusion von Fortschritt erzeugt. Die Gefahr dabei ist, dass diese Bequemlichkeit zu strategischer Blindheit führt. Ressourcen werden möglicherweise in Initiativen investiert, die zwar die Vanity Metric verbessern, aber keine echten Geschäftsziele fördern, was letztlich zu Budgetverschwendung und verpassten Chancen führt. Der Schritt weg von diesen oberflächlichen Zahlen ist daher ebenso eine kulturelle wie eine technische Herausforderung.
Dieser Artikel verfolgt drei zentrale Ziele:
- Eine rigorose und systematische Analyse der Gründe, warum die Gesamtzahl der Anfragen eine unzureichende und irreführende Metrik ist, basierend auf 16 distinkten Fehlerquellen.
- Die Verankerung dieser Analyse in etablierten Managementtheorien, um die systemischen Ursachen für das Versagen solcher Kennzahlen zu erklären.
- Die Vorstellung eines umfassenden, handlungsorientierten Frameworks für die API-Messung, das echte Einblicke in den Zustand, die Akzeptanz und den Geschäftswert einer API liefert.
2. Die Anatomie einer irreführenden Metrik: Kritische Fehlerquellen bei der reinen Request-Zählung
Eine detaillierte Untersuchung der reinen Request-Zählung als Erfolgsindikator offenbart zahlreiche Schwachstellen. Diese lassen sich in vier thematische Kategorien einteilen: technisches Rauschen, architektonische Verzerrungen, fehlender Geschäftskontext sowie verdeckte Qualitäts- und Effizienzmängel.
2.1. Technisches Rauschen und Operative Artefakte: Wenn mehr Traffic kein Mehrwert ist
Ein signifikanter Teil des API-Traffics entsteht nicht durch genuine Nutzerinteraktionen, sondern durch automatisierte technische Prozesse. Die Gesamtzahl der Anfragen vermischt diese unterschiedlichen Quellen und führt zu einer verfälschten Wahrnehmung der tatsächlichen Nutzung.
Retry-Inflation Moderne Client-Anwendungen und Frameworks implementieren standardmäßig automatische Wiederholungsversuche (Retries), wenn eine API-Anfrage fehlschlägt, beispielsweise durch einen Timeout oder einen serverseitigen Fehler (HTTP-Statuscode 5xx). Diese Retries sind aus Resilienzgründen sinnvoll, blähen die Anzahl der Anfragen jedoch künstlich auf. Eine hohe Anzahl von Wiederholungsversuchen ist in Wahrheit ein negatives Signal, das auf Probleme mit der API-Stabilität, der Netzwerkinfrastruktur oder einer zu aggressiven Timeout-Konfiguration hindeutet. Paradoxerweise trägt dieses negative Signal positiv zur Vanity Metric bei und maskiert so ein zugrunde liegendes Qualitätsproblem.
Last- und Penetrationstests Interne Aktivitäten wie Lasttests, Penetrationstests, Security Scans oder Chaos-Engineering-Experimente sind für die Aufrechterhaltung einer robusten und sicheren Plattform unerlässlich. Diese Tests können jedoch Millionen von Anfragen in kurzer Zeit generieren. Wenn dieser Traffic nicht von der Messung des produktiven Traffics getrennt wird, verunreinigt er die Daten erheblich. Eine Steigerung der Anfragen könnte lediglich eine erhöhte Testfrequenz widerspiegeln und hat keinerlei Bezug zur externen Nutzung oder zum Geschäftswert. Die Metrik wird zu einem unzuverlässigen Indikator für das Nutzerverhalten.
Chatty Clients Eine einzige, schlecht optimierte Client-Anwendung kann für einen unverhältnismäßig hohen Anteil des gesamten API-Traffics verantwortlich sein. Solches „geschwätziges“ Verhalten kann durch verschiedene Anti-Pattern entstehen, wie zum Beispiel häufiges Polling zur Statusabfrage anstelle der Nutzung von Webhooks oder Push-Benachrichtigungen, das Abrufen von Daten in vielen kleinen, repetitiven Anfragen anstatt in einem gebündelten Aufruf oder eine ineffiziente Client-Logik. Die Gesamtzahl der Anfragen kann nicht zwischen dem Traffic von hunderten gesunden, effizienten Clients und dem Lärm eines einzigen fehlerhaften Clients unterscheiden. Ein Anstieg der Metrik könnte fälschlicherweise als breite Akzeptanz interpretiert werden, obwohl er in Wirklichkeit auf ein technisches Problem bei einem einzigen Partner hindeutet.
2.2. Architektonische und Strategische Verzerrungen: Wie technische Entscheidungen die Zahlen verzerren
Technische und strategische Entscheidungen im Lebenszyklus einer API haben direkte Auswirkungen auf das Anfragevolumen. Ohne diesen Kontext führt die Interpretation der reinen Zahlen zwangsläufig zu Fehlinterpretationen.
Änderungen im API-Design Architektonische Weiterentwicklungen, wie die Aufspaltung eines monolithischen Endpunkts in mehrere granulare Microservices oder die Einführung von Paginierung zur besseren Handhabung großer Datenmengen, führen naturgemäß zu einer Erhöhung der API-Aufrufe pro Geschäftsvorgang. Um beispielsweise eine Liste von 100 Verträgen abzurufen, die zuvor mit einem einzigen Aufruf möglich war, könnten nach Einführung einer Paginierung mit einer Seitengröße von 20 nun fünf Aufrufe erforderlich sein. In diesem Fall ist ein Anstieg der Anfragen eine direkte und erwartete Folge einer positiven Designentscheidung, die die Performance und Skalierbarkeit verbessert. Die Metrik signalisiert „Wachstum“, obwohl sich die Geschäftsaktivität nicht verändert hat.
Traffic-Verschiebungen (Intern ↔ Extern) Ein klassisches Beispiel ist die Migration eines internen Systems, wie eines On-Premise-Batch-Jobs, in eine Cloud-Umgebung, die nun über die öffentliche API mit dem Kernsystem kommuniziert. Diese technische Umstellung kann das gemessene API-Volumen drastisch erhöhen, da zuvor interne Funktionsaufrufe nun zu externen API-Anfragen werden. Es entsteht jedoch kein neues Geschäft und kein neuer externer Partner wird angebunden. Die Metrik meldet fälschlicherweise ein Wachstum, wo lediglich eine Änderung der Infrastruktur stattgefunden hat.
Geänderte Caching-Strategie Caching-Strategien haben einen enormen Einfluss auf das Anfragevolumen. Eine Reduzierung des serverseitigen oder CDN-Cachings (z. B. durch eine Verkürzung der Time-to-Live, TTL) führt zu mehr Anfragen an der Ursprungs-API. Dies lässt die Metrik besser aussehen, kann aber gleichzeitig die Latenz für den Endnutzer erhöhen und die Betriebskosten steigern. Umgekehrt führt die Implementierung einer aggressiveren Caching-Strategie zu weniger Anfragen, was als Rückgang interpretiert werden könnte, obwohl es sich um eine positive technische Optimierung handelt, die die Performance verbessert und Kosten senkt. Die Metrik bestraft somit gute Ingenieurspraxis und belohnt potenziell schlechte.
API zu langsam / zu schlecht (Client-Side Caching as a Defense) Dieser Punkt offenbart eine besonders problematische Dynamik. Wenn eine API als langsam oder unzuverlässig wahrgenommen wird (z. B. eine hohe p95-Latenz aufweist), sind die Entwickler der konsumierenden Anwendungen gezwungen, defensive Maßnahmen zu ergreifen. Eine gängige Strategie ist das aggressive clientseitige Caching oder Pre-Fetching. Der Client fragt proaktiv Daten ab, von denen er annimmt, dass der Nutzer sie bald benötigen könnte, um sie lokal zwischenzuspeichern. Dadurch soll vermieden werden, dass der Nutzer auf die langsame Antwort der API warten muss.
Dies führt zu einem Teufelskreis:
- Die API des Anbieters ist langsam und hat eine hohe Latenz.
- Der Konsument implementiert als Gegenmaßnahme aggressives Polling oder Pre-Fetching, was ihn zu einem „geschwätzigen Client“ macht.
- Dieses Verhalten erhöht das gesamte Anfragevolumen, das vom Anbieter gemessen wird.
- Der Anbieter feiert das „Wachstum“ der Vanity Metric, ohne die Ursache zu erkennen.
- Der erhöhte Traffic belastet die bereits überlastete Infrastruktur zusätzlich, was die Latenz weiter verschlechtern und die Betriebskosten in die Höhe treiben kann.
- Die eigentliche Ursache — die langsame API — wird nie behoben, da die primäre Kennzahl ein positives Bild zeichnet. Die „Lösung“ auf der Client-Seite verschärft das Problem auf der Anbieter-Seite.
2.3. Fehlender Geschäfts- und Wertkontext: Die Verbindung zum Business kappen
Die gravierendste Schwäche der reinen Request-Zählung ist ihre vollständige Entkopplung vom Geschäftskontext. Sie misst Aktivität, aber nicht Wertschöpfung.
Fehlende Normalisierung Eine absolute Zahl wie „25 Millionen Anfragen“ ist ohne Bezugsgröße bedeutungslos. Um aussagekräftig zu sein, muss sie normalisiert werden. Relevante Normalisierungen wären Anfragen pro aktivem Nutzer, Anfragen pro Partner oder — die aussagekräftigste Variante —
Anfragen pro Geschäftsvorfall. Wie viele API-Aufrufe sind notwendig, um eine neue Police anzulegen oder eine Schadenmeldung zu bearbeiten? Ein sinkender Wert in dieser normalisierten Metrik deutet auf eine höhere Prozesseffizienz hin, während ein steigender Wert auf Ineffizienzen hindeutet, selbst wenn die absolute Zahl der Anfragen wächst.
„Unique Consumers“ unbekannt Die Steigerung von 23 auf 25 Millionen Anfragen könnte von einem einzigen neuen, aber ineffizient implementierten Partner stammen oder von 100 neuen, gesunden Partnern. Ohne die Anzahl der einzigartigen, aktiven Konsumenten (Unique API Consumers) zu verfolgen, ist es unmöglich zu wissen, ob die Nutzerbasis wächst oder ob nur einige wenige Power-User (oder ein fehlerhaftes System) für den Anstieg verantwortlich sind. Fallstudien, beispielsweise von der Harvard University, zeigen, dass die Verfolgung aktiver Entwickler eine zentrale Erfolgsmetrik für ein API-Programm ist, um die Reichweite und Komplexität der App-Nutzung zu verstehen.
Keine Aussage zur Feature-Adoption Ein Unternehmen investiert in die Entwicklung eines neuen, strategisch wichtigen Endpunkts, beispielsweise einer neuen API zur digitalen Schadenmeldung. Der Erfolg dieser Investition hängt davon ab, ob die Partner diese neue API auch nutzen. In der aggregierten Gesamtzahl der Anfragen ist die Nutzung dieses spezifischen Endpunkts jedoch völlig unsichtbar. Die Metrik kann die entscheidende Frage „Wird unser neues Feature angenommen?“ nicht beantworten. Die Verfolgung der Akzeptanzrate neuer Features, oft unterstützt durch Methoden wie A/B-Tests oder Feature-Flags, ist hierfür unerlässlich.
Saisonale Effekte Ein einfacher Stichtagsvergleich zwischen zwei Jahren ignoriert den Kontext von Geschäftszyklen. In der Versicherungsbranche gibt es beispielsweise typische Spitzenzeiten, wie das Jahresendgeschäft bei Kfz-Versicherungen. Marketingkampagnen, gesetzliche Fristen oder Feiertage können ebenfalls zu massiven, aber vorhersagbaren Schwankungen im Traffic führen. Ein Vergleich, der diese saisonalen Effekte nicht berücksichtigt, ist wenig aussagekräftig.
Unterschiedliche QoS-Stufen Die Metrik behandelt alle Anfragen gleich. Ein asynchroner Massen-Import von Partnerdaten mit niedrigem Service Level Agreement (SLA) wird genauso gezählt wie eine zeitkritische, synchrone Transaktion eines Premium-Partners. Die Metrik vermischt Anfragen mit völlig unterschiedlichem Geschäftswert und unterschiedlichen Qualitätsanforderungen. Sie gibt keinen Aufschluss darüber, ob der Traffic in den wertvollen, hochprioren Segmenten oder in den weniger kritischen, niedrigprioren Segmenten wächst.
2.4. Verdeckte Qualitäts- und Effizienzmängel: Was die Zahl nicht verrät
Schließlich verschleiert die reine Request-Zählung wesentliche Aspekte der Servicequalität, der Performance und der Kosteneffizienz.
Erfolgs- vs. Fehlerquote Dies ist eine der kritischsten Auslassungen. 25 Millionen Anfragen mit einer Fehlerquote von 5 % stellen eine betriebliche Katastrophe dar, verglichen mit 23 Millionen Anfragen bei einer Fehlerquote von 0,1 %. Die reine Request-Zahl ist blind gegenüber der Qualität des Services. Wie unter Retry-Inflation erläutert, kann eine steigende Anfragezahl sogar durch eine höhere Fehlerrate verursacht werden, wenn fehlgeschlagene Anfragen wiederholt werden. Die Überwachung der Fehlerrate, idealerweise aufgeschlüsselt nach Endpunkt und HTTP-Statuscode, ist eine fundamentale Anforderung an jedes professionelle API-Monitoring.
Performance-Einfluss Die Latenz der API beeinflusst das Verhalten der Clients. Eine sehr schnelle API (niedrige Latenz) könnte Clients dazu verleiten, häufiger zu pollen, was die Anzahl der Anfragen erhöht. Hier wäre das „Wachstum“ ein Artefakt der verbesserten Performance, nicht der gestiegenen Geschäftsnachfrage. Wie in “Client-Side Caching as a Defense” dargelegt, kann aber auch eine langsame API zu mehr Anfragen führen. Die Metrik ist unfähig, zwischen diesen gegensätzlichen Szenarien zu unterscheiden.
Keine Kosten-Perspektive In einer Cloud-basierten Infrastruktur ist jede API-Anfrage mit Kosten verbunden — für Rechenzeit, Bandbreite, Logging, Monitoring und mehr. Eine Steigerung der Anfragen um 8,7 % bedeutet wahrscheinlich eine mindestens ebenso hohe Steigerung der Betriebskosten. Ohne eine Metrik wie Kosten pro Anfrage oder, noch besser, Kosten pro Geschäftstransaktion feiert das Unternehmen steigende Ausgaben als Erfolg. Die Diskussion über die Effizienz und den Return on Investment (ROI) der Plattform findet nicht statt.
Kein Kontext zu Kapazität Die Zahl von 25 Millionen Anfragen sagt nichts über die Auslastung des Systems aus. Läuft die Plattform bei 95 % ihrer Kapazitätsgrenze und steht kurz vor einem Ausfall, oder läuft sie bei 10 % und ist massiv überprovisioniert und damit zu teuer? Ohne einen Vergleich mit den Kapazitätsgrenzen des Systems ist die Zahl zur Steuerung des Betriebs unbrauchbar.
3. Theoretische Fundierung: Goodharts Gesetz und der Kobra-Effekt in der Unternehmenspraxis
Die Schwächen der reinen Request-Zählung sind keine isolierten Phänomene, sondern manifestieren sich als klassische Beispiele für gut dokumentierte Effekte aus der Management- und Wirtschaftstheorie. Zwei Konzepte sind hierbei besonders relevant: das Gesetz von Goodhart und der Kobra-Effekt.
3.1 Goodhart’s Law: “Wenn eine Kennzahl zum Ziel wird, taugt sie nicht mehr als Kennzahl”
Das nach dem britischen Ökonomen Charles Goodhart benannte Gesetz besagt: „When a measure becomes a target, it ceases to be a good measure“. Der Kernmechanismus dahinter ist, dass Menschen ihr Verhalten so optimieren, dass sie die Zielmetrik maximieren, oft auf eine Weise, die dem ursprünglichen, übergeordneten Ziel schadet. Wenn Mitarbeiter oder Teams wissen, dass sie an einer bestimmten Zahl gemessen werden, werden sie Wege finden, diese Zahl zu verbessern, selbst wenn dies negative Nebenwirkungen hat.
Die direkte Anwendung auf den API-Kontext ist offensichtlich: Wenn die Gesamtzahl der Anfragen in Sprint-Reviews als primäre Erfolgsmetrik präsentiert wird, wird sie implizit oder explizit zu einem Ziel. Teams könnten daraufhin Entscheidungen treffen, die diese Zahl erhöhen, auch wenn sie der Gesamteffizienz, Stabilität oder dem Geschäftswert der Plattform schaden. Beispiele hierfür sind:
- Das Design „geschwätziger“ Clients wird nicht hinterfragt, da sie zur Zielerreichung beitragen.
- Eine Reduzierung des Cachings wird in Erwägung gezogen, um mehr Traffic an der Ursprungs-API zu generieren.
- Die Migration interner Systeme auf die öffentliche API wird als „Wachstum“ gefeiert, obwohl kein neuer Geschäftswert entsteht.
Goodharts Gesetz erklärt somit systematisch, warum die Fokussierung auf eine solch simple Metrik zu den in Abschnitt 2 beschriebenen Verzerrungen und Fehlinterpretationen führt.
3.2 The Cobra Effect: Wenn gut gemeinte Anreize nach hinten losgehen
Der Kobra-Effekt beschreibt eine Situation, in der ein gut gemeinter Anreiz eine perverse, unbeabsichtigte Konsequenz hat, die das ursprüngliche Problem verschlimmert. Der Name geht auf eine Anekdote aus der britischen Kolonialzeit in Indien zurück. Um die Plage von Giftschlangen in Delhi zu bekämpfen, setzte die Regierung eine Prämie für jede getötete Kobra aus. Dies führte jedoch dazu, dass findige Bürger begannen, Kobras zu züchten, um die Prämie zu kassieren. Als die Regierung das Programm einstellte, ließen die Züchter ihre nun wertlosen Schlangen frei, was die Kobrapopulation in der Stadt dramatisch erhöhte und das Problem verschlimmerte.
Ein bekanntes Beispiel aus der Geschäftswelt ist der Wells-Fargo-Kontenbetrugsskandal. Das Unternehmen führte aggressive Verkaufsziele und Anreize für Mitarbeiter ein, um die Anzahl der pro Kunde eröffneten Konten zu erhöhen. Dieser Anreiz führte dazu, dass Mitarbeiter Millionen von Konten ohne Zustimmung der Kunden eröffneten, um ihre Quoten zu erfüllen. Der kurzfristige Erfolg bei der Zielerreichung führte zu einem massiven Reputationsschaden, hohen Strafen und dem Verlust von Kundenvertrauen — das genaue Gegenteil des eigentlichen Ziels, die Kundenbeziehungen zu stärken.
Im API-Kontext ist der „Anreiz“ die positive Darstellung einer wachsenden Anfragezahl. Die „perverse Konsequenz“ ist eine potenziell weniger effiziente, teurere und qualitativ schlechtere API-Plattform. Die Fokussierung auf die falsche Metrik lenkt von den eigentlichen Problemen ab und kann dazu führen, dass diese sich unbemerkt verschlimmern — genau wie die Kobrapopulation in Delhi.
Die wichtigste Erkenntnis aus diesen Theorien ist, dass der Weg nach vorne nicht darin besteht, einfach eine neue, einzelne Zielmetrik zu finden. Auch eine Fokussierung allein auf „Uptime“ könnte zu unerwünschtem Verhalten führen, etwa wenn Teams aus Angst vor Ausfällen auf riskante, aber wertvolle Innovationen verzichten. Die Lösung liegt vielmehr in der Einführung eines ausgewogenen Systems von Kennzahlen, das ein ganzheitliches Bild liefert. Dies knüpft an eine moderne Interpretation von Goodharts Gesetz an, die von John Cutler formuliert wurde: In einer Umgebung mit hoher psychologischer Sicherheit und Vertrauen kann eine Kennzahl auch dann eine gute Kennzahl bleiben, wenn sie ein Ziel ist, weil das Verfehlen des Ziels als wertvolles Signal für kontinuierliche Verbesserung behandelt wird. Dies verschiebt den Zweck der Messung von reiner Beurteilung hin zu einem Werkzeug für gemeinsames Lernen und strategische Anpassung.
4. Der Paradigmenwechsel: Ein Framework für aussagekräftige API-Metriken
Um von irreführenden Vanity Metrics zu handlungsorientierten Erkenntnissen zu gelangen, ist ein Paradigmenwechsel erforderlich. Anstelle einer einzelnen Zahl wird ein mehrschichtiges Framework vorgeschlagen, das die API-Leistung aus drei entscheidenden Perspektiven beleuchtet: operative Exzellenz, Akzeptanz und Engagement sowie Geschäftswert und Effizienz. Diese Struktur orientiert sich an etablierten Best Practices der Branche.
4.1. Fundament: Operative Exzellenz (Operational Excellence)
Diese Metriken bilden das technische Fundament und beantworten die Frage: „Ist unsere API zuverlässig, schnell und stabil?“ Ohne eine solide operative Basis ist jeder weitere Erfolg gefährdet.
Verfügbarkeit (Uptime) Dies ist die grundlegendste Metrik und misst den prozentualen Anteil der Zeit, in der die API betriebsbereit ist und Anfragen erfolgreich entgegennimmt. Obwohl sie basal ist, ist sie eine nicht verhandelbare Grundlage für die Servicequalität und oft ein zentraler Bestandteil von Service Level Agreements (SLAs). Eine typische Zielgröße liegt bei 99,9 % oder höher.
Latenz (Latency — p95/p99) Die Latenz misst die Zeit, die eine API benötigt, um eine Anfrage zu bearbeiten und eine Antwort zu senden. Sie ist entscheidend für die User Experience. Die Messung der durchschnittlichen Latenz ist jedoch unzureichend, da sie von wenigen sehr schnellen Anfragen geschönt und von wenigen sehr langsamen Ausreißern verzerrt werden kann. Aussagekräftiger ist die Messung von Perzentilen, insbesondere der Tail Latency. Die p95-Latenz gibt den Wert an, den 95 % der Anfragen nicht überschreiten. Sie zeigt die Erfahrung der langsamsten 5 % der Nutzer und ist ein hervorragender Indikator für die Performance unter Last. Eine Fallstudie einer Reisesuch-API zeigt eindrücklich die Wirkung: Durch gezielte Optimierungen konnte die p95-Latenz von schmerzhaften 10 Sekunden auf 2 Sekunden reduziert werden, was zu einer drastisch verbesserten Nutzerzufriedenheit und geringeren Absprungraten führte. Die p99-Latenz beleuchtet die Erfahrung der langsamsten 1 % und ist für die Analyse von Extremfällen relevant.
Fehlerrate (Error Rate) Diese Metrik misst den prozentualen Anteil der Anfragen, die zu einem Fehler führen. Eine hohe Fehlerrate deutet auf Qualitätsprobleme hin und untergräbt das Vertrauen der Nutzer. Für eine sinnvolle Analyse muss die Fehlerrate weiter aufgeschlüsselt werden:
Nach HTTP-Statuscode-Klasse Eine Unterscheidung zwischen Client-Fehlern (4xx, z. B. 400 Bad Request, 401 Unauthorized) und Server-Fehlern (5xx, z. B. 500 Internal Server Error) ist essenziell. 4xx-Fehler deuten auf Probleme auf der Client-Seite hin (z. B. fehlerhafte Anfragen, ungültige Authentifizierung), während 5xx-Fehler auf Probleme in der eigenen Infrastruktur oder Anwendung hinweisen.
Pro Endpunkt Die aggregierte Fehlerrate kann täuschen. Es ist entscheidend, die Fehlerrate für jeden einzelnen Endpunkt zu überwachen. Eine hohe Fehlerrate von 5 % bei einem kritischen Endpunkt wie /submitClaim ist weitaus alarmierender als bei einem weniger wichtigen oder veralteten Endpunkt.
4.2. Reichweite: Adoption und Engagement (Adoption and Engagement)
Diese Metriken beantworten die Frage: „Wird unsere API genutzt und ist sie für Entwickler einfach zu verwenden?“ Sie messen die externe Wirkung und die Qualität der Developer Experience.
Aktive API-Konsumenten (Unique API Consumers) Anstatt der Gesamtzahl der Anfragen wird hier die Anzahl der einzigartigen Entwickler, Partner oder Anwendungen gezählt, die in einem bestimmten Zeitraum (z. B. pro Monat) mindestens eine erfolgreiche API-Anfrage gestellt haben. Diese Metrik ist der wahre Indikator für die Reichweite und das Wachstum der Nutzerbasis der API.
Time to First Hello World (TTFHW) Diese Metrik misst die Zeit, die ein neuer Entwickler benötigt, um sich zu registrieren, einen API-Schlüssel zu erhalten, die Dokumentation zu verstehen und die erste erfolgreiche, sinnvolle API-Anfrage zu stellen. Eine kurze TTFHW ist ein starkes Indiz für eine exzellente Developer Experience, gute Dokumentation und einen reibungslosen Onboarding-Prozess. Sie ist ein entscheidender Faktor für die Konversionsrate von Interessenten zu aktiven Nutzern.
Adoptionsrate neuer Features (Feature Adoption Rate) Wenn ein neuer Endpunkt oder eine wesentliche neue Funktionalität veröffentlicht wird, sollte deren Akzeptanz gezielt verfolgt werden. Wie viele der aktiven Konsumenten nutzen das neue Feature innerhalb der ersten Wochen oder Monate? Diese Metrik gibt direktes Feedback über den wahrgenommenen Wert und die Auffindbarkeit von Neuentwicklungen. Methoden wie A/B-Tests oder die Steuerung über Feature-Flags können hierbei helfen, verschiedene Ansätze zur Einführung neuer Funktionen zu vergleichen und die Adoption zu maximieren.
4.3. Wertschöpfung: Geschäftswert und Effizienz (Business Value and Efficiency)
Diese Metriken stellen die direkte Verbindung zum Geschäftserfolg her und beantworten die Frage: „Schafft unsere API auf effiziente Weise einen Mehrwert für das Unternehmen?“
API-Aufrufe pro Geschäftsvorfall (API Calls per Business Event) Dies ist wohl die wirkungsvollste kontextbezogene Metrik. Anstatt die absolute Anzahl der Anfragen zu zählen, wird die Anzahl der Aufrufe gemessen, die zur Durchführung eines spezifischen Geschäftsvorfalls erforderlich sind — zum Beispiel pro abgeschlossener Versicherungspolice, pro eingereichter Schadenmeldung oder pro Onboarding eines neuen Vertriebspartners. Ein sinkender Trend bei dieser Kennzahl ist oft ein Zeichen für steigende Prozesseffizienz, da dasselbe Geschäftsergebnis mit weniger technischem Aufwand erreicht wird.
Wachstum pro Marktsegment (Growth per Market Segment) Die API-Nutzung sollte nach relevanten Geschäftssegmenten aufgeschlüsselt werden. Dies können Partnertypen (z. B. Makler, Vergleichsportale), Geschäftsbereiche (z. B. Leben, Kranken, Sach) oder geografische Regionen sein. Diese Segmentierung ermöglicht es, zu erkennen, in welchen Märkten die API an Zugkraft gewinnt und wo möglicherweise Nachholbedarf besteht. Diese Erkenntnisse können direkt in die Geschäfts- und Vertriebsstrategie einfließen.
Kosten pro Transaktion / 1.000 Requests (Cost per Transaction / 1k Requests) Diese Metrik verbindet die API-Nutzung direkt mit den Betriebskosten. Sie erzwingt eine Diskussion über die Kosteneffizienz der Plattform. Die Berechnung erfordert ein Verständnis der zugrunde liegenden Infrastrukturkosten (Server, Bandbreite, Datenbanken), der Wartungsaufwände und des personellen Aufwands. Das Ziel ist nicht zwangsläufig, die Kosten zu minimieren, sondern ein optimales Verhältnis von Kosten zu generiertem Geschäftswert zu erreichen und die Skalierbarkeit der Kostenstruktur zu verstehen.
5. Implementierung in der Praxis: Vom Einzelwert zum aussagekräftigen Dashboard
Der Übergang von einer einzelnen Vanity Metric zu einem umfassenden Framework erfordert eine Anpassung der Reporting-Strukturen, insbesondere in wiederkehrenden Formaten wie dem Sprint-Review. Anstatt eine einzelne, irreführende Zahl zu präsentieren, sollte ein ausgewogenes Dashboard — ein „Business-Cockpit“ — etabliert werden, das ein ganzheitliches Bild der API-Performance vermittelt.
Die folgende Tabelle dient als Blaupause für ein solches Dashboard. Sie stellt die alte Metrik den neuen, kontextualisierten Kennzahlen gegenüber und zeigt auf, welche Erkenntnisse aus den jeweiligen Werten abgeleitet werden können. Der Wert dieser Darstellung liegt in ihrer Fähigkeit, abstrakte Konzepte greifbar und direkt auf den Unternehmenskontext anwendbar zu machen. Sie adressiert das Kernproblem, indem sie den Mangel an Tiefe der alten Metrik visuell und inhaltlich dem Reichtum des neuen Frameworks gegenüberstellt. Die beispielhaften Daten sind so gewählt, dass sie eine nuancierte Geschichte erzählen: Das reine Volumen steigt, aber gleichzeitig sinken Qualität und Effizienz, während die Partnerakzeptanz gesund wächst. Dies demonstriert, wie eine einzelne Zahl in die Irre führen kann und warum eine holistische Sichtweise für fundierte Geschäftsentscheidungen unerlässlich ist.
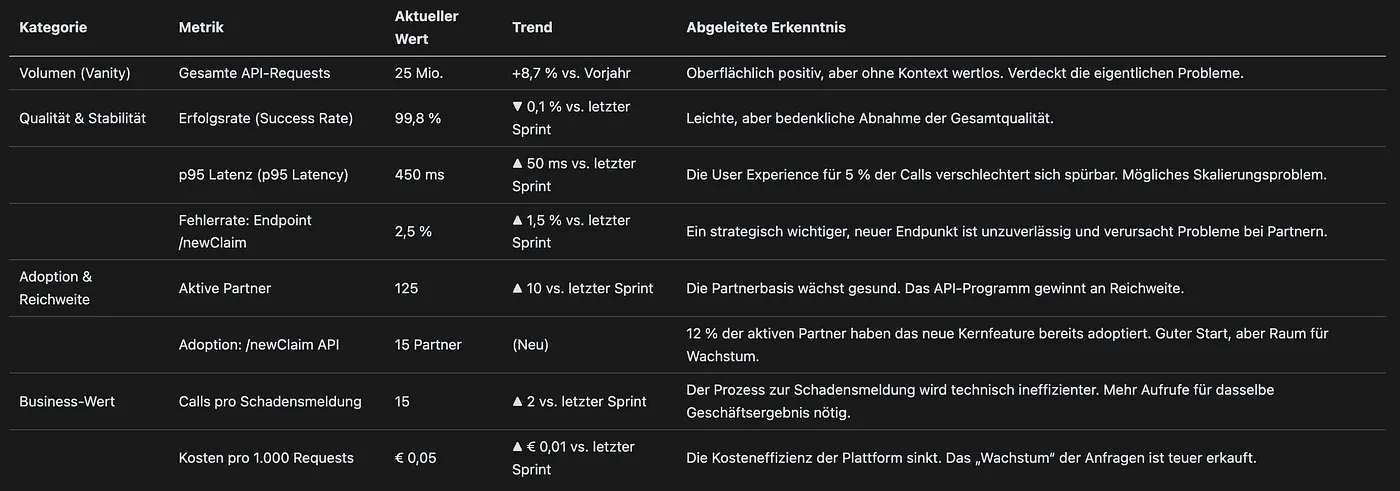
Diese tabellarische Darstellung transformiert die Diskussion. Anstatt eines einfachen „Die Zahl ist gestiegen“, ermöglicht sie eine strategische Konversation. Fragen, die sich aus diesem Dashboard ergeben, sind beispielsweise:
- „Warum sinkt unsere Erfolgsrate, obwohl wir mehr Partner gewinnen? Gibt es ein Onboarding-Problem?“
- „Die Latenz steigt. Sind unsere Skalierungsmechanismen ausreichend für das wachsende Volumen?“
- „Der neue
/newClaim-Endpunkt hat eine hohe Fehlerrate. Müssen wir die Dokumentation verbessern oder gibt es einen Bug, der die Adoption bremst?“ - „Wir benötigen mehr Aufrufe pro Schadenmeldung. Ist das API-Design suboptimal oder nutzen unsere Partner die API ineffizient?“
6. Fazit und Handlungsempfehlungen
Die Analyse hat gezeigt, dass die Fokussierung auf eine einzelne Vanity Metric wie die Gesamtzahl der API-Anfragen nicht nur unzureichend, sondern aktiv schädlich ist. Sie fördert gemäß Goodharts Gesetz falsche Verhaltensweisen, kann gemäß dem Kobra-Effekt zu einer Verschlechterung der Gesamtsituation führen und verschleiert kritische Einblicke in Systemzustand, Kosten und Geschäftswert. Ein Anstieg dieser Zahl kann auf eine Vielzahl von Ursachen zurückzuführen sein — von positivem Wachstum über technische Ineffizienzen und Qualitätsprobleme bis hin zu reinen Artefakten aus internen Prozessen.
Die Lösung liegt nicht darin, eine einzelne Kennzahl durch eine andere zu ersetzen, sondern darin, ein ausgewogenes System von Metriken zu etablieren. Das vorgestellte dreistufige Framework — bestehend aus Operativer Exzellenz, Adoption und Engagement sowie Geschäftswert und Effizienz — bietet eine ganzheitliche, ausgewogene und handlungsorientierte Sicht auf die Leistung des API-Programms. Es ermöglicht Teams, die richtigen Fragen zu stellen und datengestützte Entscheidungen zu treffen, die sowohl die technische Qualität als auch den Geschäftserfolg fördern.
Die zentrale Handlungsempfehlung geht über die bloße Änderung der Metriken auf einer Präsentationsfolie hinaus. Es ist ein Aufruf zu einem Kulturwandel. Das Ziel muss sein, eine Kultur der datengestützten Neugier und der kontinuierlichen Verbesserung zu fördern, in der Metriken dazu dienen, intelligentere Fragen zu stellen, statt einfache Antworten zu liefern. Der Sprint-Review sollte sich von einem reinen Reporting von Zahlen zu einer strategischen Diskussion entwickeln, die sich darum dreht, was diese Zahlen für das Geschäft, seine Partner und seine Kunden bedeuten. Der ultimative Zweck ist der Wandel von einem „guten Gefühl“ bei großen Zahlen hin zu „intelligenten Entscheidungen“ auf Basis der richtigen Daten. Nur so kann sichergestellt werden, dass Investitionen in die API-Plattform direkt zum langfristigen Erfolg des Unternehmens beitragen.